
This blog is the first in a planned series, aimed at describing how some of the current SDN offerings (NSX, DFA, and ACI) work from a practical perspective. I’ll explain the title in a moment. (Updated 1/7/14.)
Concerning this blog series: I’m a networking person, so I want to know how the packets move. Software architecture diagrams are all well and good. But I want a more concrete perspective, what I call the “who does what to whom, when” level, still mostly at an overview level. I assume that such an approach might have some value for the rest of the networking community. I certainly like having the Big Picture of how things work when it comes to troubleshooting!
Product-wise, this series of blogs will stick to VMware NSX, Cisco DFA (Dynamic Fabric Automation), and Cisco ACI (Application Centric Infrastructure). These products have the dominant vendor mind- and market-share, and are likely to have much greater impact than SDN and other control products from smaller vendors. NSX/DFA/ACI provide enough similarities and differences to make discussion interesting (I hope and trust), without transgressing into mind-numbing detail (“TMI”). I thought about abbreviating NSX/DFA/ACI as the meta-acronym N/D/A. Then I thought better of it: too much potential for confusion with legal NDA documents.
Disclaimer: This and subsequent blogs in this thread are based primarily on slideware and presentations. I’ll do the best I can with the information and time available. All three products are still somewhat undocumented, with NSX being a bit further along than the other two. No, I don’t have access to DFA or ACI yet. Nor do I have a NSX lab. Constructive comments with corrections, missing information, etc. would be appreciated!
Update (1/7/14): Thanks to those who have provided input, positive feedback, corrections, and details not yet publicly visible. In particular, thanks to Dmitri Kalintsev (@dkalintsev) of VMware. He has some interesting blogs at SapientNetworks.com, which maps to http://telecomoccasionally.wordpress.com. Dmitri was kind enough to spend a solid chunk of time going over some details of NSX. Any errors are due to my interpretation of his explanation of VMware slideware.
My purpose with this series of blogs is to try to get key ideas and flavor across. So I’m going to save some of the details I’ve learned for a separate blog. For now I’ll note that NSX for Multi-Hypervisors is (my wording) closer to the base Nicira NVP product, with the NSX for vSphere product aimed at tighter VMware integration. The two products support different features. My impression is that NSX is a work in progress, aimed at being a single product, just as e.g. the various Cisco Nexus switches support different features. Marketing materials may tend to not dwell on the changing details to avoid creating confusion. For now, let me refer the reader to http://blog.ipspace.net/2013/08/what-is-vmware-nsx.html.
The All-Seeing Eye
The title for this blog comes from a common technical approach in NSX, DFA, and ACI — and probably other SDN and virtualization platforms as well. Each of these systems has a central way to track the location of every connected host (or most of them). This is the “all-seeing eye” the title refers to.
Short version: The controller (or some entity) knows everything about the end devices or VMs ARP information (MAC and IP addresses) and their location! Each of the three platforms does things somewhat differently.
 This image is supposed to suggest the blog theme of the all-seeing eye. I also thought any hint of money (well, U.S. currency) might catch your attention.
This image is supposed to suggest the blog theme of the all-seeing eye. I also thought any hint of money (well, U.S. currency) might catch your attention.
The central. tracking of device identities (MAC, IP) and location (which switch port) changes how the network processes ARP traffic, among other things. I’ve previously found that understanding how ARP is handled is quite useful for understanding FabricPath, TRILL, and OTV. So it seems useful to approach NSX / DFA / ACI via ARP as well.
I will say the word “LANE” (as in ATM LAN Emulation) at this point. The concept of “what device do we reach various MAC or IP addresses via” has come back again. This time, in IP tunnel form rather than ATM circuit form. The details of how each approach works are quite different. (Thank goodness!)
What Does NSX Know and How Does It Know It?
In NSX, the NSX controller knows which hypervisor host each VM is running on. It is the “All Seeing Eye”. The NSX controller is informed (MAC, IP addresses, hypervisor host, virtual network connections) whenever a new VM is started up. The NSX controller then populates virtual switching tables on each hypervisor. It also creates VXLAN (GRE, STT) tunnels between hypervisor hosts, whenever a new host is added. From the virtual switch perspective, the tunnels are just more interfaces to switch traffic out of, albeit with added encapsulation, a tunnel header. (Added 1/7/14: The tunnels are stateless, and only created to a hypervisor host if it has a VM attached to the relevant VXLAN / logical switch.)
There is a choice of GRE, STT, or VXLAN tunneling (with encrypted tunnels for remote sites). (1/7/14: This depends on which NSX product is used: NSX/M-H uses GRE or STT, with optional IPsec, NSX/vSphere uses VXLAN). We will assume VXLAN since that appears to be the leading candidate. Which encapsulation is used really doesn’t matter much, or shouldn’t, soon, once NIC and CPU chips can process the encapsulation efficiently.
When traffic has to get between VMs on the same VMware host, NSX locally switches the traffic as it would with a vSwitch or dvSwitch. When traffic has to reach another VMware host, VMware uses a VXLAN tunnel between the IP addresses of the two VMware hosts in question. That is, MAC to hypervisor IP mapping is part of the switching tables in the hypervisor virtual switches. (This sort of approach should sound familiar if you know how Cisco FabricPath and OTV work.)
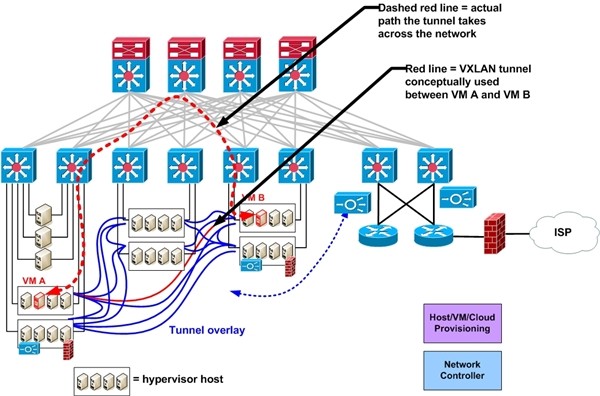
About the drawing: It looks a lot cleaner when you leave out the network part of the diagram. Network people find that hard to do. I originally tried drawing the blue VXLAN tunnel lines over the switch infrastructure. That got very messy very fast!
I plan to cover L2 forwarding in more detail in the next blog in this series.
NSX can have hypervisor hosts acting as VXLAN to VLAN gateways, or VTEP’s. NSX uses “ovsdb-proto” for switch table updates to hypervisor hosts and VTEPs. NSX can also have third-party devices (Palo Alto firewalls, F5 application delivery controllers) that are registered as VTEPs. It appears that a VMware VTEP is expected to inform the NSX controller of any learned MAC addresses, so that it can update switching tables.
A non-NSX-compatible VXLAN to VLAN gateway is unlikely to participate in communicating ARP information (MAC and IP addresses) to the NSX controller. However, any hypervisor host containing a VM that sent such an ARP should be able to process the ARP reply, learn the ARP information, and update the controller.
In NSX, the VTEP hypervisor hosts normally do ARP caching, to reduce ARP flooding.
It appears that ARP flooding is still apparently needed to acquire information for physical hosts and devices, or where third party VXLAN gateways are used at L2. Any NSX hypervisor host needs to associate a physical device MAC with the IP address of the VXLAN gateway to forward traffic to. NSX chooses one VXLAN to VLAN gateway as active forwarder for a given VXLAN/VLAN. If there are others, they are passive. A “L2 default route” is apparently used for unknown MAC addresses (i.e. they are forwarded to the active VXLAN gateway). .
NSX can flood BUM (Broadcast, Unknown, Multicast) L2 traffic when needed. It has three ways it can do so:
- A source hypervisor host can send a copy out each connected VXLAN or other tunnel interface. At some point, this becomes a scaling problem. (1/7/14: One unicast copy is sent to a “UTEP” for each remote VTEP subnet. It then replicates to other VTEPs on that remote subnet. Advantage: works without network IPmc support, other than IGMP querier. Intelligence: only hits segments where there is a VM attached to the VXLAN in question.)
- A “service node” can offload the packet replication for BUM traffic. (Reminiscent of BUS server in ATM LANE?) (1/7/14: Only supported in NSX/M-H.)
- A hybrid approach can be used, where the source host sends multicast in its local segment (VLAN), and unicast tunnel copies to VTEPs in every other subnet (who proxy and forward it as multicast locally). (1/7/14: Requires IGMP support; IGMP querier. Also intelligent about scope: only goes to segments where a VM is attached to the VXLAN.)
This preserves the L2 semantics for BUM flooding within a VLAN. Using a “L2 default route” gets L2 BUM traffic out to the physical world efficiently.
Bottom line: NSX is smart about what it does. It has great visibility into the virtual world, and a bit less visibility into the physical world. One might not totally like active / passive VXLAN to VLAN gateways as far as high availability. Simple programming is more likely to work?
NSX may be touted as running over generic switches with minimal configuration (in the extreme, devices with just enough switching or routing to provide inter-hypervisor connectivity). Then it becomes a “leave the networking to us” approach. If I were doing that, I’d want to make sure I had solid visibility into any performance issues in the underlay network.
Thanks again to Ivan Pepelnjak, Brad Hedlund, and Scott Lowe for their webinar on NSX Architecture. See http://demo.ipspace.net/bin/list?id=NSXArch. Good information, and still one of the best public sources of NSX information I’ve found. Any errors in interpretation are mine, not theirs.
What Does DFA Know and How Does It Know It?
DFA is deployed in a spine-and-leaf topology with appropriate model Cisco hardware (switches, NXOS code, and line cards supporting DFA). It uses Cisco DCNM as a Central Point of Management (CPOM). But DCNM is not the All Seeing Eye for DFA.
DFA host learning occurs when physical or virtual edge devices (physical hosts, VMs) are connected or instantiated. This triggers vSphere and / or DCNM to configure the relevant switch port settings, among other things. The actual learning is based on any of the following:
- VDP (VSI Discovery and Configuration Protocol), which is part of 802.1Qbg (clause 41). Cisco Nexusw 1000v and OVS (Open Virtual Switch) support it. VMware and NSX appear not to do so. See also http://blog.ipspace.net/2011/05/edge-virtual-bridging-evb-8021qbg-eases.html.
- DHCP
- ARP-ND
- Data packets
This is where the innovative part of DFA comes in. Each edge device will have a MAC address, an IP address, possibly a VLAN, and a segment ID (think VRF or tenant it belongs to). These are all advertised via MP-BGP to the spine switches, which act as BGP route reflectors. Yes, they really are talking about up to 1,000,000 /32 host routes.
As far as ARP, the edge switch a host or VM is connected to locally terminates it if the destination IP is known. It responds with its own virtual MAC. It then forwards traffic on behalf of the host. The same happens if a host sends ARP for the MAC of the default gateway.
For the curious, the forwarding mechanism is routing into essentially an enhanced FabricPath tunnel, using NSH encapsulation to support service chaining. I plan to explain this in more depth on this in a subsequent blog.
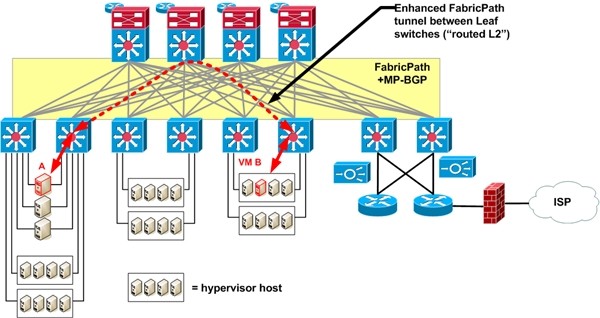
The Cancun CiscoLive presentation on DFA is the best public source of information I know of. Cisco Partners were treated in December to some more detailed presentations. They do not show up when I look at Milan CiscoLive sessions for the end of January 2014 however. I imagine your Cisco Partner or SE / TME might be able to help if you’re interested.
CiscoLive Orlando DFA presentation: https://www.ciscolive.com/online/connect/sessionDetail.ww?SESSION_ID=7774
CiscoLive Cancun DFA presentation: https://www.ciscolive.com/online/connect/sessionDetail.ww?SESSION_ID=74976
What Does ACI Know and How Does It Know It?
A lot of what I have read about ACI seems similar to DFA. For example, there is built-in multi-tenant capability. There is talk of supporting 1 million IPv4 and IPv6 end devices.Leaf switches track local directly connected entries and remote (global) entries.
One key difference between ACI and DFA is the ACI has a central controller, APIC, for policy.
The Spine switches track the full database of which MAC and IP addresses reside behind which leaf switch. (That is “LISP like”, if that helps: separation of ID from Location.). The mechanism used has been described as a “distributed mapping database.” Unfortunately, that’s almost exactly how I think of BGP. The Spine switches also have to track all the active policy information for each edge device. So whether MP-BGP is involved or not, it behooves us to think of the Spine switches as having a {MAC, IP, related policy item} distributed database. The exact form of the database would be nice to know. Its speed, robustness and convergence / update / failure properties are likely more important to us.
I’m refusing to speculate further here — generally advisable sometime before firmly implanting both feet in one’s mouth.
ACI uses something similar to Cisco FabricPath conversational learning. So Leaf switches will only need to cache information for the flows (conversations) that pass through them. That should help scaling.
ACI supports learning about new end devices and automated configuration of the switches. The details of how exactly this happens are still a bit vague. One detail: the APIC policy apparently can (will) create port groups in vCenter. When the VMware administrator instantiates VMs the APIC can then get the right policy applied to the relevant leaf switch ports. I presume that by then the APIC knows the MAC and IP addresses, and tenant / context of the VM. The Cisco 1000v or the ACI AVS (Application Virtual Switch, follow-on to 1000v for ACI) apparently may facilitate the new device provisioning process — details TBD.
I’m guessing that the discovery methods listed for DFA apply as well, particularly for newly attached physical servers. The Leaf switch must inform the APIC about the new device to receive the appropriate configuration as well as connectivity policy information. It caches the latter: all policy information relevant to the new device as source or destination. The APIC also informs the Spine switches of the new end device and policy information. The Spine switches are used for a fast policy lookup when a policy cache miss occurs on a Leaf switch.
One info gap here is how the relevant Leaf switch and port are identified and configured, also how the APIC knows which tenant is relevant. The VMware or Cloud Management System integration should be able to provide most of that information for the virtual edge device scenario. (I’m stuck on how the physical Leaf port is identified.) For physical edge devices (also known as bare metal servers), it seems that administrator assistance or some other information (DNS name?) is likely needed. Minor details the slideware has skipped over so far — but things one might need to know to troubleshoot a problem.
ARP is handled by the Leaf switch forwarding the ARP directly to the relevant Leaf switch and end point, with no flooding. That’s possible because APIC knows all (and passes active information on to the Spine switches).
If you’re eager to learn more, documentation is expected around the time ACI is formally released.
ACI forwarding uses VXLAN tunneling with an embedded NSH segment (or eVXLAN) header. Every Leaf switch will act as default gateway for every local VLAN. ACI can terminate VXLAN (and other tunnel encapsulations) at Leaf switches, enabling it to provide full manageability and visibility within the switch fabric. Along with hardware VXLAN gateway performance.
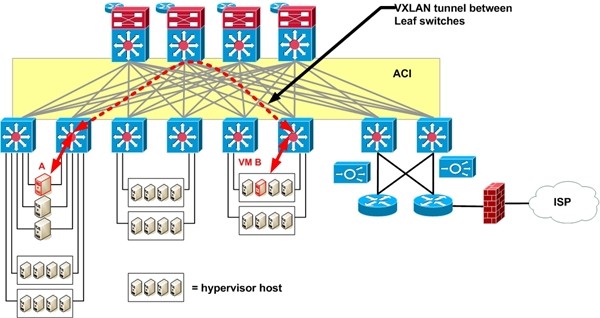
Other Tidbits
There are some corner cases relating to ARP and BUM flooding that one might want to know about: silent hosts, and unknown MAC addresses. We’ll leave those as an exercise for the reader.
Thought (Challenge Exercise / Info TBD): How well does NSX interact with NSX? Both expect to control service chaining, security and other functions. Will they play well together, or do they overlap and compete too much? How well does NSX active / passive play with ACI’s VXLAN termination? Is vSphere going to be the preferred VMware product to pair with ACI?
Relevant Prior Posts
- Thinking About NSX, DFA, and ACI
- Application Centric Networking After-Thoughts
- The Cisco ACI Launch, Part 2
- The Cisco / Insieme ACI Launch, Part 1
Life Log
I hope your holidays were as pleasant as mine. Our four kids (now grown) were able to visit for a couple of days then back to work. And it was nice having some downtime. Among other things, I suspect that getting bored when 1/1 rolls around is another sign I’m not ready to retire!
Twitter: @pjwelcher

Great Blog and great Post,
It really helps us the technical guys to understand how things work from the network perspective.
Thanks you Pete.
Really great post!
Pete,
do you think that VMW may have an advantage in SDN VS Cisco becouse of its dominance in the virtualization world?
Hi Pete,
There is complete information available on Cisco DFA at http://www.cisco.com/go/dfa, on the Product Support tab.
cheers,
suran.
Thanks Suran. As you’ll see in one of the later blogs, I got around to checking the DFA pages, around the end of January/early February. I’d describe what I found there as a lot better, with some remaining gaps. I recognize it takes time to get all that collateral up. I also checked out the documentation area and that was picking up some good content. So folks interested in DFA should definitely keep looking!
Just saw this comment and posted it. VMware has mind-share among the server folks, who have more $$ to spend in general. They also may be receptive to the "don’t need any stinking network equipment" message some of the more aggressive VMware sales types are putting out. And hey, there’s pretty good performance on virtual appliances, e.g. maybe good enough for small shops, say change over time.
Thanks for sharing the extra miles.
You mentioned:
1/7/14: This depends on which NSX product is used: NSX/M-H uses GRE or STT, with optional IPsec, NSX/vSphere uses VXLAN
Do you know why NSX/M-H only supports GRE or STT?
Why doesn’t NSX/M-H support VXLAN as well? That’s pretty typical in Openstack.
No I don’t know. NSX/M-H is older product? R&D going into the new?
Good question for VMware! Will NSX/M-H evolve with feature parity? Is that appropriate, useful?